冒泡排序
|
|
Swap 函数:
|
|
选择排序
|
|
直接插入排序
插入排序的思想有点像打扑克抓牌的时候,我们插入扑克牌的做法。想象一下,抓牌时,我们都是把抓到的牌按顺序放在手中。因此每抓一张新牌,我们都将其插入到已有的排好序的手牌当中,
当前抓到第i张牌key = a[i],让其与排好顺序的i-1张牌,从后往前比较,大于key的话就往后移,直到遇到一个不大于key的牌,将key插入到这个位置后面。
|
|
希尔排序
先将整个待排元素序列分割成若干个子序列(由相隔某个“增量”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。
其实希尔排序就是对相隔若干距离的数据进行直接插入排序。
|
|
归并排序
归并排序的主要思想是分治法(Divide and Conquer)。
首先考虑下如何将将二个有序数列合并。这个非常简单,只要从比较二个数列的第一个数,谁小就先取谁,取了后就在对应数列中删除这个数。然后再进行比较,如果有数列为空,那直接将另一个数列的数据依次取出即可。
然后分治递归实现合并排序。
|
|
快速排序
即挖坑填数+分治。
挖坑填数:
i = l;j = r; 将基准数key挖出形成第一个坑a[i]。j--由后向前找比它小的数,找到后挖出此数填前一个坑a[i]中。i++由前向后找比它大的数,找到后也挖出此数填到前一个坑a[j]中。- 再重复执行2,3二步,直到
i == j,将基准数key填入a[i]中。
|
|
堆排序
堆的定义
二叉堆是完全二叉树或者是近似完全二叉树。
二叉堆满足两个特性:
- 父结点的键值总是大于或等于(小于或等于)任何一个子节点的键值。
- 每个结点的左子树和右子树都是一个二叉堆(都是最大堆或最小堆)。
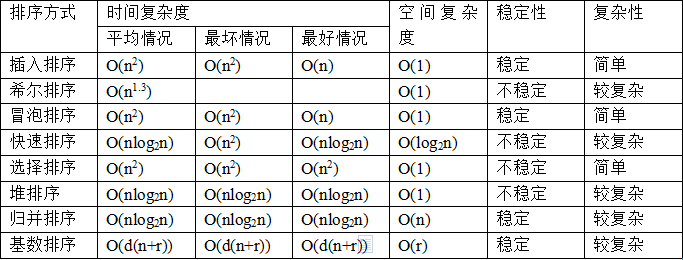
当父结点的键值总是大于或等于任何一个子节点的键值时为最大堆。当父结点的键值总是小于或等于任何一个子节点的键值时为最小堆。下图展示一个最小堆:
堆的储存
一般都用数组来表示堆,i结点的父结点下标就为(i–1)/2。它的左右子结点下标分别为2*i+1和2*i+2。如第0个结点左右子结点下标分别为1和2。上图堆的储存结构为:
| 10 | 15 | 30 | 40 |
|---|---|---|---|
堆的操作
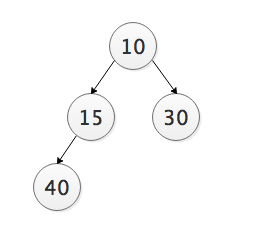
建立堆:数组具有对应的树的表示形式。一般情况下,树并不能满足堆的条件,通过重新排列元素,可以建立堆化树。
初始表: 40 10 30, 堆化树:10 40 30
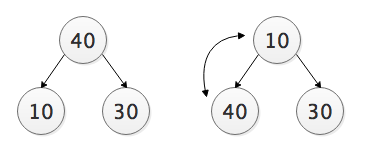
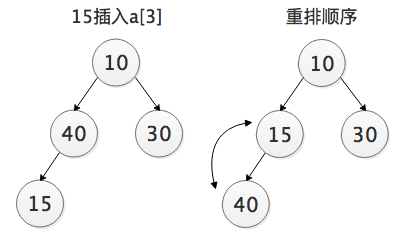
插入一个元素:新元素被加入到最底层,随后树被更新恢复堆,如下面将15加入表中。
删除一个元素:删除总发生在根节点,最后一个元素用来填补空缺位置,结果树更新恢复堆。
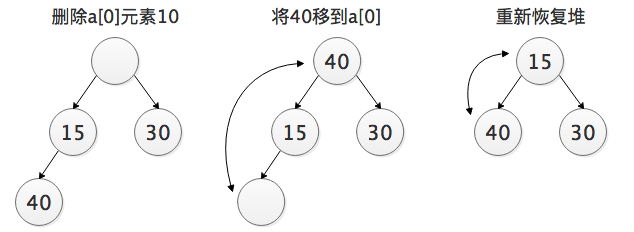
由以上分析我们可以得知,插入操作其实就是一个从下往上调整的过程:
将元素插入到最后,从下往上与其父节点比较,小于父节点则交换,重复这个过程直到根节点。这是一个“上浮”的过程。
|
|
而删除操作则是一个从上往下调整的过程:
先删除根节点,将最后一个元素插入到根节点,从上往下与其左右节点比较,大于左右节点中最小的一个则交换,重复这个过程直到比左右节点都小,这时就不用调整了。这是一个“下沉”的过程。
|
|
讲完FixUp和FixDown操作之后,给定一个无序数组,我们可以很方便的建立起一个堆。
从最后一个元素(n-1)的父节点开始,到根节点进行FixDown操作,就能建立起一个最小堆了。
|
|
堆排序
首先可以看到堆建好之后堆中第0个数据是堆中最小的数据。取出这个数据再执行下堆的删除操作。这样堆中第0个数据又是堆中最小的数据,重复上述步骤直至堆中只有一个数据时就直接取出这个数据。
由于堆也是用数组模拟的,故堆化数组后,第一次将a[0]与a[n-1]交换,再对a[0...n-2]重新恢复堆。第二次将a[0]与a[n–2]交换,再对a[0...n-3]重新恢复堆,重复这样的操作直到a[0]与a[1]交换。由于每次都是将最小的数据并入到后面的有序区间,故操作完成后整个数组就有序了。有点类似于直接选择排序。
|
|
注意使用最小堆排序后是递减数组,要得到递增数组,可以使用最大堆。
由于每次重新恢复堆的时间复杂度为O(logN),共N-1次重新恢复堆操作,再加上前面建立堆时N/2次向下调整,每次调整时间复杂度也为O(logN)。二次操作时间相加还是O(N*logN)。故堆排序的时间复杂度为O(N*logN)。
排序总结